摘要
基于视觉的自主导航系统依赖于快速准确的物体检测算法来避免障碍物。为了适应部署所使用的硬件能量有限,这类系统所设计的算法和传感器需要具备计算效率。受生物启发的事件相机由于其速度快、能量效率高以及对不同光照条件的稳健性,成为这类系统的理想视觉传感器。然而,传统的计算机视觉算法无法处理基于事件的输出,因为它们缺乏光强度和纹理等光度特征。在本研究中,我们提出了一种新颖的技术,利用事件中固有的时间信息高效地检测移动物体。我们的技术包括一个轻量级的脉冲神经网络架构,能够根据相应物体的速度将事件分离。然后,这些分离的事件在空间上进一步进行分组以确定物体边界。这种物体检测方法既是异步的,又对相机噪声具有鲁棒性。此外,在背景中由静态物体生成事件的场景中,该方法表现出良好的性能,而现有的基于事件的算法则失败了。我们展示了通过利用我们的架构,自主导航系统在执行物体检测时可以具有最小的延迟和能量开销。
介绍
自主导航作为一个重要的研究领域正在兴起,其应用范围从偏远地区的摄影和监视到人口稠密的城市交通系统。自动化工程师协会(SAE)确定了自主导航的六个级别[1],从没有自动化的系统(级别 0)到完全自动化且不需要任何操作员的系统(级别 5)。具备自动化功能(级别 1 及以上)的系统最基本和最重要的要求之一是能够检测和避免障碍物。而且最重要的是,这些系统必须能够在非常高的速度下准确执行物体检测。
最近,成像技术的进步导致了生物启发式事件相机的发展[2][5]。传统的帧相机以固定间隔捕捉光强和纹理等光度特征,而事件相机是异步的,只捕捉每个像素的光强变化。虽然事件相机无法捕捉光度特征,但它们不会受到运动模糊等问题的影响,并且可以以更高的频率和更广泛的光照范围进行操作。由于事件相机具有更高的输出频率,它们可以捕捉到帧相机所错过的高分辨率时间信息。由于物体检测和随后的碰撞避免等应用需要在非常高的速度和广泛的光照范围内进行,事件相机成为理想的候选器。
虽然已经有大量关于物体和特征检测算法的研究,但其中大多数算法都是针对帧相机输出设计的。这些算法在事件相机输出上失败,因为它们依赖于仅存在于帧数据中的光度特征。例如,图 1 显示了一个初步的边缘检测算法(Canny 滤波器)[6]和一个基于复杂学习的物体识别算法(YOLOv 3)[7]在相同场景的帧相机输出和事件相机输出上的性能。虽然这些算法在前者上能够成功运行,但在后者上却无法运行。

这促使我们探索和利用事件中固有的时间特征,但在传统的计算机视觉算法中被忽视了。在事件中利用这些时间信息可以帮助我们检测和区分场景中的对象。为此,我们确定了两个对对象检测很重要的属性:
(i) 由同一对象生成的事件在时间上彼此接近。
(ii)同一对象生成的事件在空间上彼此接近。
基于这两个特性,我们的目标是在空间和时间两个维度上对事件进行分组,以根据它们的源对象来隔离事件并识别对象边界。受生物启发的脉冲神经元,特别是漏电整流和放电(LIF)神经元[9],可以利用时空信息,因此非常适合在这两个维度上实现边界检测。这些神经元模仿大脑活动,并根据输入信号的时间特性行为。只有当输入事件的发生频率高于某个特定频率时,神经元才会产生输出脉冲。具有这些脉冲神经元的神经结构对输入事件的时间结构敏感。还可以通过网络安排这些神经元之间的连接,以支持空间上彼此接近的事件。
此外,脉冲神经元以异步方式工作,使其与事件相机的异步输出兼容。这些特性以及脉冲神经结构可以比其人工神经对应物更节能(如[10]–[12]所示),使其成为执行具有低延迟和能量开销的自主导航系统中的对象检测的理想选择。在这项工作中,我们开发了一种新颖且节能的对象检测技术,首先根据对象的运动速度来隔离对象。这是通过使用事件相机和轻量级单层脉冲神经网络的输入来实现的。一旦根据运动速度将对象分离开来,然后根据它们的空间特征将它们对应的事件分组在一起。
为此,我们利用现有的聚类技术进一步将属于不同对象的事件根据它们的空间接近程度进行分离。在这里,我们利用了同一对象的事件具有相似的时间特征(如运动速度)和空间特征(如由空间上接近的像素生成)的事实。我们的实验表明,这种方法在延迟和能量消耗方面是一种更高效的检测对象的方式。通过根据相应对象的运动速度隔离事件,我们还能够消除噪声和背景静态对象引起的非相关信息。此外,由于需要进行聚类的样本(事件)数量减少,这有助于降低聚类技术的操作复杂性。
我们将主要贡献总结如下:
- 我们开发了一种仅依赖事件相机输出而不需要传统帧相机的任何额外信息的目标检测算法。
- 与许多现有的目标检测方法不同,它们需要在一段时间内累积事件来创建一帧,如果需要检测静态物体,我们可以通过对未通过脉冲架构传播的剩余事件进行聚类来实现。我们在事件相机生成事件的同时异步执行目标检测。
- 提出的基于脉冲的网络用于根据物体的运动分离物体,由单层组成,从而实现具有较低延迟和能量开销的检测算法。
- 所提出的脉冲架构的输出(根据速度隔离物体)可以与任何不需要先验知识的空间聚类技术一起使用,无论是聚类的数量还是大小。
- 脉冲架构是场景无关的。这意味着我们不需要根据部署场景来训练架构的参数。这些参数直接对应于物体的速度,并可以在部署之前进行微调。
相关工作
A. 事件摄像机领域中的对象检测
目标检测是计算机视觉界广泛研究的一个主题。已经有了从简单的特征检测器[6]、[13]到更复杂的基于学习的方法[14]的工作。学习界对神经网络也非常感兴趣,它不仅可以检测对象,还可以将它们分类为不同的类别[7]。然而,当涉及到对象分类不是优先事项的自主导航时,底层算法的延迟和能效优先。
如前所述,由于缺乏诸如纹理和光强度之类的光度特性,传统的基于帧的算法无法对事件相机输出进行操作。然而,由于事件摄像机的众多优点,包括更高的操作速度、更宽的动态范围和更低的功耗,社区对开发更适合该领域的算法产生了极大的兴趣。
最初的基于事件的检测算法,如[15]、[16],专注于检测事件摄像机输出中存在的模式。作者在[17]中使用了一个简单的斑点检测器来检测事件数据中存在的固有模式,[18]中使用了事件分布的平面拟合方法来识别角点。最近的一项工作采用高斯混合建模来检测事件数据中的模式[19]。然而,这些方法在后台生成事件的情况下会失败。作为一种解决方案,[20]提出了一种运动补偿技术,通过估计系统的自我运动来消除背景产生的事件。然而,所涉及的优化给系统增加了显著的延迟和计算开销。
为了提高检测精度,最近的几项研究工作集中在利用帧和事件相机的信息[21],[22]。这些混合方法检测帧上的特征,并通过事件跟踪对象。由于它们的检测依赖于帧输入,因此它们无法在具有宽动态范围的场景中操作,并且计算成本高昂。还通过在预先指定的持续时间内累积事件来创建密集描述符或“帧”[23],[24]。然后,这些框架可以与传统的计算机视觉算法一起使用。但是,由于输入的不兼容性,这些实现显示出较低的准确性。为了克服这个问题,许多学习方法,如[25]-[29],用这样的帧作为输入来训练卷积神经网络(CNNs)。然而,这样的系统仍然增加了延迟的开销,并且本质上不是异步的。此外,随着深度神经网络的使用,计算能力开销增加。
B. 用于处理事件的 Spiking 神经结构
脉冲神经网络(SNNs)以异步方式运行,可以缓解基于学习的技术中遇到的延迟问题。[30]中的作者使用无监督学习技术来学习由事件相机捕获的高速公路上的车辆轨迹。[31]–[35]中的研究利用 SNNs 不仅可以检测对象,还可以对其进行分类。然而,这些研究使用了深度 SNNs,给系统增加了显著的计算和延迟开销。它们还需要密集的训练技术,并且在部署到与训练网络不同的场景时会失去准确性。
在本文中,我们提出了一个仅包含单层脉冲神经元的网络,以捕捉事件数据中存在的时间信息。这减轻了神经结构的能量和延迟开销。此外,该网络不需要在大量数据上进行训练,而是在部署之前仅需对超参数进行微调。与其他研究不同的是,我们观察到,当我们的算法在不同的部署场景中进行测试时,准确性没有下降。
C. 事件的空间聚类
聚类技术,如[36]–[38],在将低维复杂度的样本进行分组时非常有用。由于事件可以被视为具有空间和时间维度的样本,因此人们一直试图利用聚类技术来对事件进行分组并检测相应的对象边界。[39]使用了在[38]中提出的均值漂移聚类方法来对事件进行聚类,而[40]则使用了图谱聚类技术来对事件进行分组以确定对象边界。然而,这些技术假设只有移动物体会产生事件。在这里提出的方法中,我们首先消除了由背景和相机噪声产生的事件,从而使得可以使用空间聚类技术。由于在部署之前对象的数量和大小都是未知的,我们采用与这些参数无关的聚类技术[37]。
方法
A. 在时域中分离对象
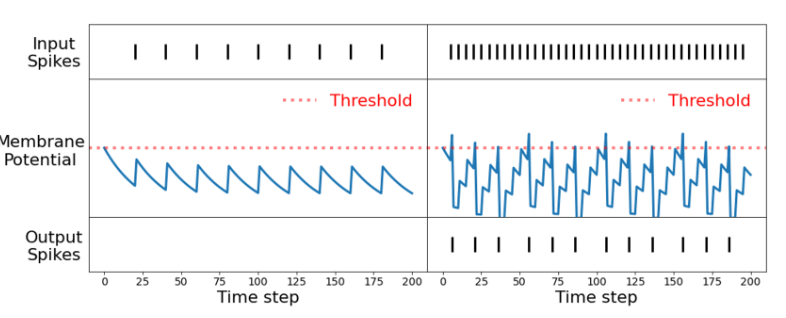
如在第一节中提到的,为了高效地检测物体,我们的目标是在时间和空间领域中分离物体。脉冲神经元是一个很好的选择,因为它们能够在时间领域内进行操作。LIF 神经元模型[9]具有两个特征。一个是称为膜电位(
这样的神经元对输入数据中存在的时间信息是敏感的。通过调整超参数(阈值和泄漏因子),可以识别在时间上彼此接近的输入尖峰。这种现象如图 2 所示。如果输入尖峰之间的时间较大,则膜电势在达到阈值之前衰减其值。然而,如果这些输入发生得更频繁,它们能够克服衰减并将膜电势增加到阈值。因此,如果输入事件以高于特定值的频率发生,则神经元产生输出尖峰。另一方面,当作用在像素上的光强度随时间变化时,事件相机会生成事件。生成这些事件的速率将取决于场景或对象移动的速度。因此,移动速度更快的物体将负责以高得多的频率生成事件。当尖峰神经元的这些特性和事件数据结合在一起时,我们就有了一个对移动速度超过一定速度的物体敏感的网络。
直接将事件相机的每个像素连接到一个脉冲神经元会测量该像素输入的频率,但不一定能测量物体的速度。让我们考虑图 3 中所示的情景。在这里,一个物体在时间步骤
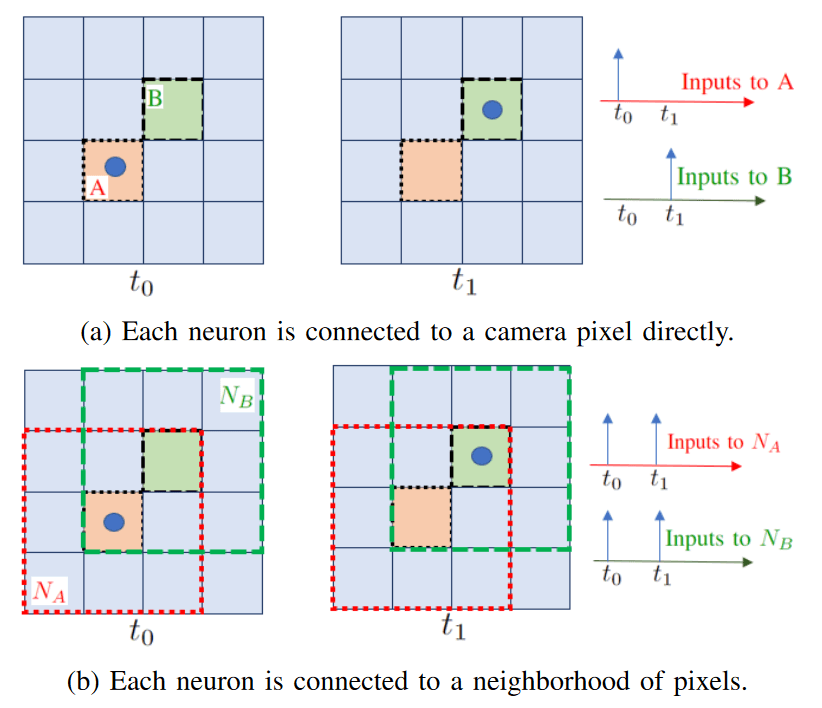
因此,如图 4 所示,我们将一个 (3×3)的像素加权邻域作为每个神经元的输入。邻域的权重被归一化为总和为 1。中心像素被赋予权重 0.2,而其他像素被赋予相等的权重 0.1。这使得我们的架构能够更高效地检测场景 0中的高速物体。
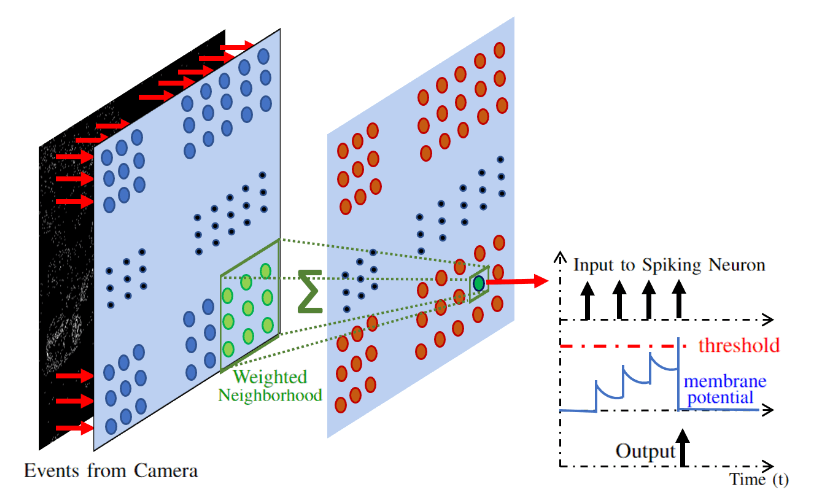
一旦我们使用神经网络结构来检测快速移动的物体,我们需要在将它们在空间域中分离之前,将输入事件与这些物体对应起来。为了做到这一点,我们会恢复与脉冲输出周围邻域相关的输入。恢复邻域的大小可以进行调整,并不限于神经元输入邻域的大小。我们的脉冲层将以一个时间步的延迟异步地工作(以检查输出脉冲并恢复导致该输出的上一个时间步的输入)。与许多现有方法不同,这种方法不需要在使用之前将事件数据积累一段时间。图 5 展示了使用 MVSEC 数据集[8]中的场景来演示所提出的脉冲架构的操作。
B. 空间域中的聚类
为了检测和绘制准确的物体边界,我们在分离的输入事件上使用空间聚类。虽然有许多广泛可用的聚类技术,但大多数要求我们在聚类之前要么知道聚类的大小,要么知道数据中的聚类数量。由于我们没有任何关于输入场景的先验知识,我们需要一种与这两个因素都无关的聚类技术。在我们的实验中,我们选择了一种基于密度的技术,称为密度聚类(DBSC)[37]。这种技术仅需要两个参数:形成一个聚类所需的最小数据点数和聚类的最小数据密度。这两个参数都经过了精调以获得最佳结果。
C. 扩展到多个速度
到目前为止,我们已经提出了一种尖峰神经块,可以将运动的物体与静止的物体区分开来。虽然这很有用,并且已经显示了在现实世界场景中对象检测的改进,但我们可以根据对象的速度进一步分离对象。图 6。显示了可用于根据对象的速度分离对象的体系结构的概述。
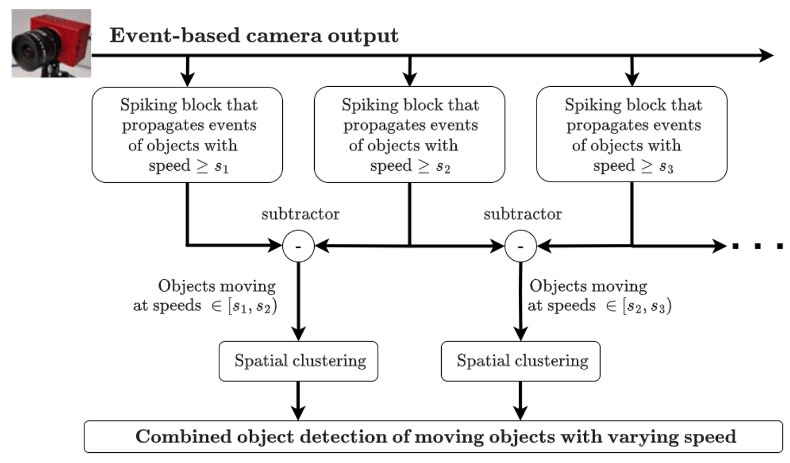
这个架构的每个分支将隔离移动速度超过某个特定速度的物体。通过考虑具有连续阈值速度 s 1 和 s 2 的分支输出之间的差异,我们可以隔离速度在
实验与结果
在本节中,我们定性和定量地展示了我们提出的技术的准确性和能量效率。大多数现有的研究在作者生成的私有数据集上评估其算法。这些数据集对公众不可用,并且不类似于在真实场景中生成的事件相机输出。为了在真实场景中衡量我们算法的准确性和能量效率,我们选择了 MVSEC 数据集[8] 来展示我们的结果。这是一个公开可用的数据集,其中包含由事件相机和安装在汽车上的传统帧相机收集的数据。
A. 准确率
如前所述,大多数现有作品只能在没有任何背景或相机噪音的场景中运行。然而,我们的算法在这些条件下可以很好地工作。这是因为,尖峰结构充当时间滤波器,可以消除来自相机的噪声输入以及背景中静态对象生成的事件。
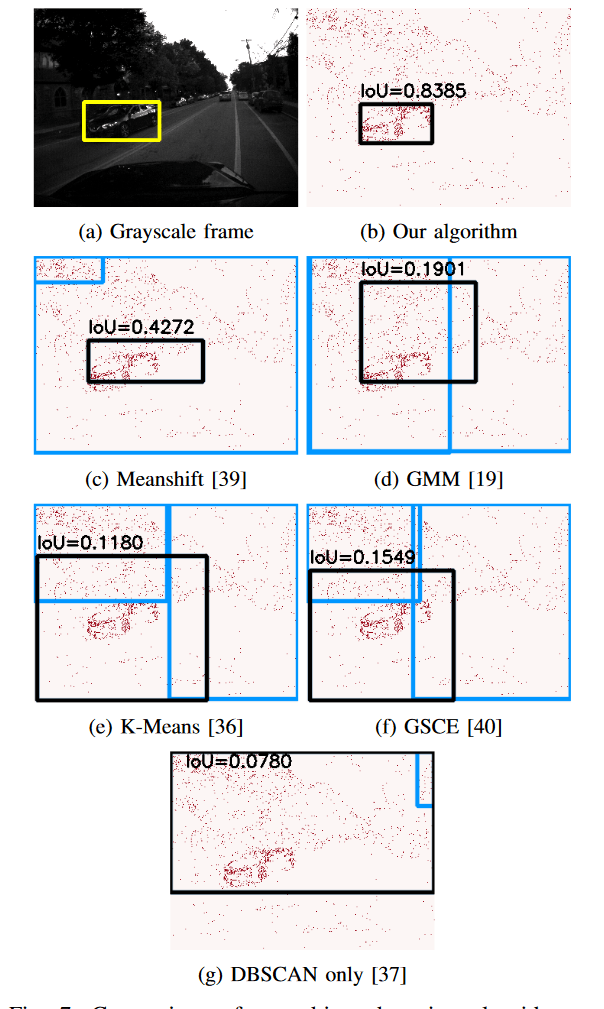
由于 MVSEC 数据集不包含前景中对象的真实边界框,我们使用 YOLOv 3[7],这是一种传统的基于帧的现有技术算法,在相应的灰度图像上生成边界框。我们将其作为基本事实,然后比较前景中存在的对象(非静态)的并集交集(IoU)。由于灰度图像是以低得多的速率生成的,因此我们只计算这些时间帧下基于事件的检测算法的 IoU。然而,需要注意的是,我们的检测算法是异步的,并且可以按照事件摄像机生成事件的速率进行操作。
我们将 IoU(交并比)≥ 0.5 的边界框视为真正阳性(TP),而 IoU < 0.5 的边界框视为假阴性(FN)。如果在未检测到相应的真实边界框时生成了一个边界框,我们将其视为假阳性(FP)。根据它们的标准定义,通过使用 TP、FN 和 FP 计算了精确度和召回率。表 I 显示了 MVSEC 数据集室外第 2 天段的检测算法在这些准确度指标上的比较。
| Algorithm | Mean IoU | Recall | Precision |
|---|---|---|---|
| GMM | 0.2154 | 0.08 | 1.00 |
| Meanshift | 0.3986 | 0.23 | 1.00 |
| K-Means | 0.0997 | 0.00 | 0.00 |
| GSCE | 0.1071 | 0.00 | 0.00 |
| DBSCAN only | 0.1244 | 0.00 | 0.00 |
| Ours (+ DBSCAN) | 0.8593 | 1.00 | 1.00 |
| 表1:显示现有对象检测算法的精度指标与我们的算法的比较的表。实验在MVSEC数据集的室外第2天片段上进行。 |
图 7 显示了由这些算法中的每一个预测的边界框的更定性的比较。我们观察到,直接在事件摄像机输出上使用聚类技术([36],[37])无法准确检测对象。这是因为,由背景和相机噪声生成的事件可能在空间上发生在由前景(或移动对象)生成的事件附近。[39]和[19]等其他技术能够最大限度地减少假阳性的数量,但在产生大量假阴性(IoU<0.5 的框)时表现不佳。即使前景中只有一个对象,这些算法也会生成多个边界框。我们的算法在数据集的所有实例下都优于所有其他现有算法,并在生成具有良好 IoU(≥0.5)的边界框的同时,最大限度地减少了误报和假阴性的数量。为了进行更公平的比较,我们考虑相对于地面实况具有最高 IoU 的边界框,用于在生成多个边界框的算法中计算精度度量。
B. 计算效率
所提出的目标检测方法的主要优点之一是在能量和延迟方面的计算效率。脉冲神经元通过膜电位累积输入,并且仅在累积的膜电位超过设定的阈值时发出输出脉冲。与用于人工神经网络的传统乘积累加(MAC)操作相比,这些累积(AC)操作仅需要计算所需能量的一小部分。在[12]中已经证明,对于在 45 纳米 CMOS 技术上执行的 32 位浮点计算,AC 操作的能量(EAC)为 0.9 皮焦耳,而 MAC 操作的能量(EMAC)为 4.6 皮焦耳。此外,由于事件的性质,这些 AC 操作以稀疏的方式发生。请注意,当算法无法分离移动物体(7 c)-(7 g)时,可能会有覆盖整个帧的边界框。
我们可以通过将每个突触操作的数量
我们提出的技术在延迟方面也非常高效。传统的计算机视觉方法(如[7])受到帧相机输入速率的限制,而我们的算法由于事件相机的高输出速率,可以以更快的速度运行。与许多基于事件的检测算法(如[20]、[23]、[24])不同,我们也不需要在处理之前累积一段时间的事件。算法的真正异步性质最大程度地减少了我们在延迟方面的处理开销。
总结
在这项工作中,我们提出了一种新颖的目标检测算法,用于自主导航任务,该算法使用受生物启发的脉冲神经元与事件相机相结合。通过利用输入数据中固有的时间信息,所提出的脉冲架构基于物体的速度来分离事件。我们展示了我们的算法在检测物体边界方面的优秀表现,即使在存在相机噪声和背景物体的情况下,其他现有的基于事件的算法也会失败。所提出的方法具有低能量开销,这归因于输入数据的稀疏性、低网络复杂性以及脉冲神经元的计算效率高的累加(与标准深度学习中的乘法和累加相对应)操作。此外,所开发的脉冲架构与部署场景无关,并且可扩展到多种速度。
REFERENCES
[1] S. S. Shadrin and A. A. Ivanova, “Analytical review of standard SAE J 3016 taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles with latest updates,” Avtomobil’. Doroga. Infrastruktura., no. 3 (21), p. 10, 2019.
[2] A. Amir, B. Taba, D. Berg, T. Melano, J. McKinstry, C. Di Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendoza, et al., “A low power, fully event-based gesture recognition system,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7243–7252.
[3] P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128 × 128 120 db 15μs latency asynchronous temporal contrast vision sensor,” IEEE journal of solid-state circuits, vol. 43, no. 2, pp. 566–576, 2008. [4] C. Posch, D. Matolin, and R. Wohlgenannt, “A qvga 143 db dynamic range frame-free pwm image sensor with lossless pixel-level video compression and time-domain cds,” IEEE Journal of Solid-State Circuits, vol. 46, no. 1, pp. 259–275, 2010.
[5] C. Brandli, R. Berner, M. Yang, S.-C. Liu, and T. Delbruck, “A 240× 180 130 db 3 μs latency global shutter spatiotemporal vision sensor,” IEEE Journal of Solid-State Circuits, vol. 49, no. 10, pp. 2333–2341, 2014.
[6] J. Canny, “A computational approach to edge detection,” IEEE Transactions on pattern analysis and machine intelligence, no. 6, pp. 679698, 1986.
[7] J. Redmon and A. Farhadi, “Yolov 3: An incremental improvement,” arXiv, 2018. [8] A. Zihao Zhu, D. Thakur, T. Ozaslan, B. Pfrommer, V. Kumar, and K. Daniilidis, “The multi vehicle stereo event camera dataset: An event camera dataset for 3 d perception,” arXiv e-prints, pp. ArXiv–1801, 2018. [9] A. Delorme, J. Gautrais, R. Van Rullen, and S. Thorpe, “Spikenet: A simulator for modeling large networks of integrate and fire neurons,” Neurocomputing, vol. 26, pp. 989–996, 1999. [10] B. Han and K. Roy, “Deep spiking neural network: Energy efficiency through time based coding,” in European Conference on Computer Vision. Springer, 2020, pp. 388–404. [11] A. S. Kucik and G. Meoni, “Investigating spiking neural networks for energy-efficient on-board ai applications. A case study in land cover and land use classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2020–2030. [12] M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC). IEEE, 2014, pp. 10–14. [13] C. Harris, M. Stephens, et al., “A combined corner and edge detector,” in Alvey vision conference, vol. 15, no. 50. Citeseer, 1988, pp. 105244. [14] S. Xie and Z. Tu, “Holistically-nested edge detection,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1395–1403. [15] T. Delbruck and P. Lichtsteiner, “Fast sensory motor control based on event-based hybrid neuromorphic-procedural system,” in 2007 IEEE international symposium on circuits and systems. IEEE, 2007, pp. 845–848. [16] T. Delbruck and M. Lang, “Robotic goalie with 3 ms reaction time at 4% cpu load using event-based dynamic vision sensor,” Frontiers in neuroscience, vol. 7, p. 223, 2013. [17] X. Lagorce, C. Meyer, S.-H. Ieng, D. Filliat, and R. Benosman, “Asynchronous event-based multikernel algorithm for high-speed visual features tracking,” IEEE transactions on neural networks and learning systems, vol. 26, no. 8, pp. 1710–1720, 2014. [18] X. Clady, S.-H. Ieng, and R. Benosman, “Asynchronous event-based corner detection and matching,” Neural Networks, vol. 66, pp. 91–106, 2015. [19] E. Pikatkowska, A. N. Belbachir, S. Schraml, and M. Gelautz, “Spatiotemporal multiple persons tracking using dynamic vision sensor,” in 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. IEEE, 2012, pp. 35–40. [20] A. Mitrokhin, C. Fermuller, C. Parameshwara, and Y. Aloimonos, “Event-based moving object detection and tracking,” arXiv preprint arXiv: 1803.04523, 2018. [21] D. Tedaldi, G. Gallego, E. Mueggler, and D. Scaramuzza, “Feature detection and tracking with the dynamic and active-pixel vision sensor (davis),” in 2016 Second International Conference on Event-based Control, Communication, and Signal Processing (EBCCSP). IEEE, 2016, pp. 1–7. [22] D. Gehrig, H. Rebecq, G. Gallego, and D. Scaramuzza, “Eklt: Asynchronous photometric feature tracking using events and frames,” International Journal of Computer Vision, vol. 128, no. 3, pp. 601618, 2020. [23] V. Vasco, A. Glover, and C. Bartolozzi, “Fast event-based harris corner detection exploiting the advantages of event-driven cameras,” in 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2016, pp. 4144–4149. [24] E. Mueggler, C. Bartolozzi, and D. Scaramuzza, “Fast event-based corner detection,” British Machine Vision Conference (BMVC), 2017. [25] X. Clady, J.-M. Maro, S. Barr ́ e, and R. B. Benosman, “A motion-based feature for event-based pattern recognition,” Frontiers in neuroscience, vol. 10, p. 594, 2017. [26] B. Ramesh, H. Yang, G. Orchard, N. A. Le Thi, S. Zhang, and C. Xiang, “Dart: distribution aware retinal transform for event-based cameras,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 11, pp. 2767–2780, 2019. [27] A. Sironi, M. Brambilla, N. Bourdis, X. Lagorce, and R. Benosman, “Hats: Histograms of averaged time surfaces for robust event-based object classification,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1731–1740. [28] J. Li, F. Shi, W.-H. Liu, D. Zou, Q. Wang, P. K. Park, and H. Ryu, “Adaptive temporal pooling for object detection using dynamic vision sensor.” in BMVC, 2017. [29] M. Cannici, M. Ciccone, A. Romanoni, and M. Matteucci, “Asynchronous convolutional networks for object detection in neuromorphic cameras,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0. [30] O. Bichler, D. Querlioz, S. J. Thorpe, J.-P. Bourgoin, and C. Gamrat, “Extraction of temporally correlated features from dynamic vision sensors with spike-timing-dependent plasticity,” Neural networks, vol. 32, pp. 339–348, 2012. [31] P. O’Connor, D. Neil, S.-C. Liu, T. Delbruck, and M. Pfeiffer, “Realtime classification and sensor fusion with a spiking deep belief network,” Frontiers in neuroscience, vol. 7, p. 178, 2013. [32] D. Marti, M. Rigotti, M. Seok, and S. Fusi, “Energy-efficient neuromorphic classifiers,” Neural computation, vol. 28, no. 10, pp. 20112044, 2016. [33] Y. Cao, Y. Chen, and D. Khosla, “Spiking deep convolutional neural networks for energy-efficient object recognition,” International Journal of Computer Vision, vol. 113, no. 1, pp. 54–66, 2015. [34] G. Orchard, C. Meyer, R. Etienne-Cummings, C. Posch, N. Thakor, and R. Benosman, “Hfirst: A temporal approach to object recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 10, pp. 2028–2040, 2015. [35] S. Kim, S. Park, B. Na, and S. Yoon, “Spiking-yolo: spiking neural network for energy-efficient object detection,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 11 270–11 277. [36] J. A. Hartigan and M. A. Wong, “Algorithm as 136: A k-means clustering algorithm,” Journal of the royal statistical society. Series c (applied statistics), vol. 28, no. 1, pp. 100–108, 1979. [37] L. Duan, L. Xu, F. Guo, J. Lee, and B. Yan, “A local-density based spatial clustering algorithm with noise,” Information systems, vol. 32, no. 7, pp. 978–986, 2007. [38] K. G. Derpanis, “Mean shift clustering,” Lecture Notes, vol. 32, 2005. [39] G. Chen, H. Cao, M. Aafaque, J. Chen, C. Ye, F. R ̈ ohrbein, J. Conradt, K. Chen, Z. Bing, X. Liu, et al., “Neuromorphic vision based multivehicle detection and tracking for intelligent transportation system,” Journal of advanced transportation, vol. 2018, 2018. [40] A. Mondal, J. H. Giraldo, T. Bouwmans, A. S. Chowdhury, et al., “Moving object detection for event-based vision using graph spectral clustering,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 876–884.